What tools are used in a Modern Data Stack, and what do they do?
- Published on
- Written by
- Name
- Gavin Johnson
- Name
- Hanhan Wang

This post was originally published on Twilio Segment's blog.
This is the second of a 2-part series giving a primer on the Modern Data Stack. You can read the first post, "What is Modern Data Stack, and why is everyone making such a big deal about it?"
Over the past couple of years, we’ve noticed changes in the tools customers use along with Segment. At first, this expressed itself as product requests for Cloud Sources – our ETL functionality – or reverse ETL instead of SQL Traits (SQL Traits is reverse ETL that pulls data from your data warehouse into Personas). Occasionally a customer would mention using Fivetran for ETL or Hightouch for reverse ETL to compliment Segment.
So when we went back to our data-savvy customers and asked them to “show us their data stack”, we weren’t shocked to see ETL and reverse ETL tools being used. But we were surprised to see just how warehouse-centric their data architectures had become.
We noticed a pattern. We noticed similar architectures with similar tools and similar use cases being solved. When we aggregated our findings, a common 3-step process came into view:
One: All of their customer data from every system goes into a fully-managed cloud data warehouse – namely Snowflake and Google BigQuery. And not just from the usual tools – CDPs like Segment and ETL tools like Fivetran – but also loading raw data from cloud storage and, sometimes, skipping the blob storage and loading directly from Apache Kafka.
Two: Then Analytics Engineers and Data Scientists build models that make all of this data useful. One of the most common models is building identity-resolved customer profiles. It is far from the only modeling Data teams do, but it seems to be the foundation for many of the use cases they help with. Data teams use a lot of different tools to model and transform data, but, for modeling data on the warehouse, dbt is the tool of choice.
Three: After Analytics Engineers and Data Scientists have made the data useful, Data Engineers setup data pipelines with reverse ETL to send it from the warehouse to downstream destinations. A frequent use case is sending an identity-resolved audience from the data warehouse to MarTech tools. An example is using identity-resolved customer profiles to combine event data from your website with object data from Salesforce in your data warehouse, using that data to model a “likely to convert” audience, and sending that audience to an email marketing tool or Google Ads for remarketing. The use cases aren’t just for Marketing though. They extend to Sales, Support, Product, and beyond.
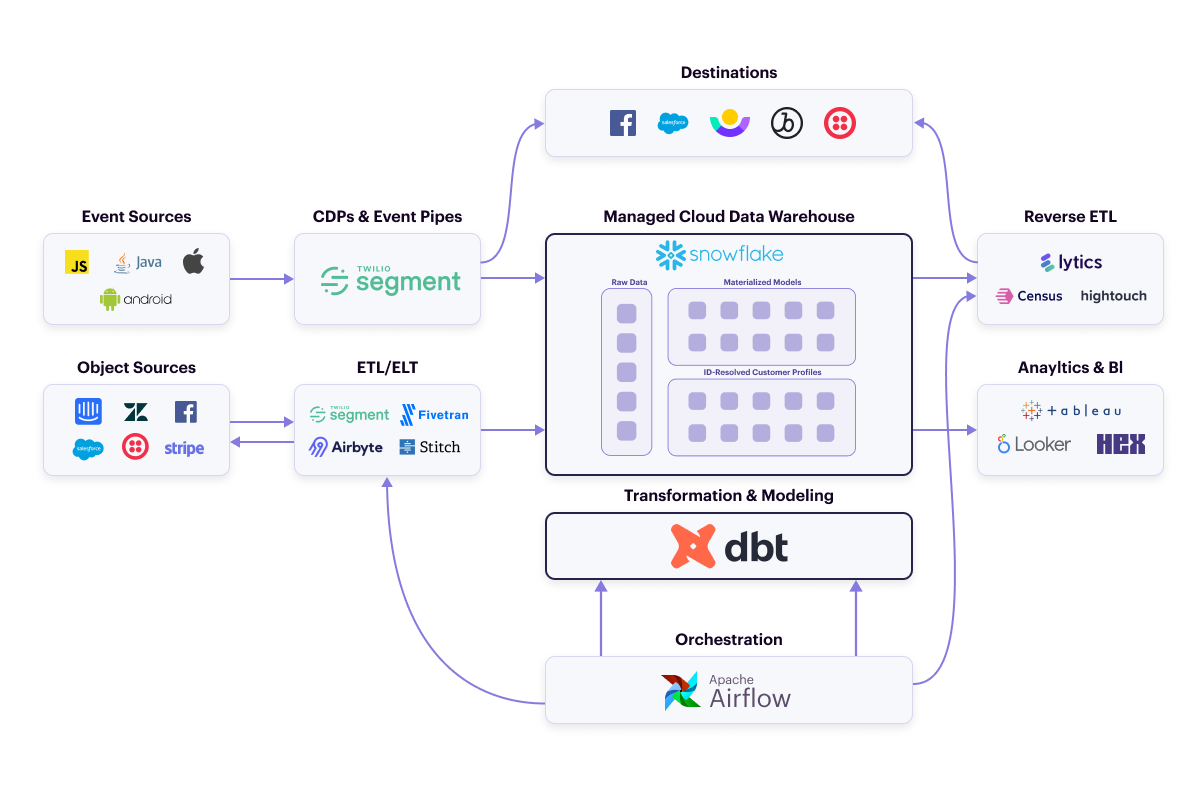
What makes up a Modern Data Stack?
Functionality
When we started analyzing all of these new warehouse-centric data stacks, we started to notice some common functionality across them. Correspondingly, tool categories have sprung up around many of these functionalities – such as data collection & pipelining, data storage, and analytics.
Below are descriptions of the different core functionalities that make up a Modern Data Stack (MDS).
Data collection & pipelining
An MDS runs on data. Data is the bare necessity. Without data – especially customer data – an MDS has no point and serves no function. The data that powers an MDS comes from a lot of sources, but there are primarily two types of data that are collected and piped to the data warehouse, event data and object data. The tools for collecting these two types of data make it simple and fast to move customer data from any source to the data warehouse.
CDPs & event pipes (for event data)
Event data comes from your websites and applications. It is behavioral data about your customers collected through their use of your digital properties. Customer Data Platforms (CDPs) are the primary tools used to collect and pipe event data. Event data can also come from IoT devices or sensors, but, in those instances, it isn’t usually customer data and is infrequently used in an MDS.
Example tools: Twilio Segment (Connections), mParticle, RudderStack, Snowplow
ETL/ELT (for Object Data)
Object data often comes from cloud applications that your business uses – Salesforce, Zendesk, SendGrid, Stripe, Facebook Ads, Google Ads, etc. – but can also come from application databases and data warehouses. Generally, it is tabular and describes the current state of something – like a customer or a process. You collect and pipe object data with ETL tools.
Example tools: Twilio Segment (Cloud Sources), Airbyte, Fivetran, Stitch
Reverse ETL
An MDS not only has to provide the functionality to bring data into the data warehouse, but it also has to provide pipelines out of the warehouse as well. A new type of tool, Reverse ETL, satisfies that requirement.
Reverse ETL tools sync data from the data warehouse into the tools your business teams use. They formalize integrations from your data warehouse out to destination applications in the same way Segment first formalized event streaming integrations. The most popular use cases focus on building identity-resolved customer profiles – modeled and stored in the data warehouse – and using Reverse ETL to send derivatives like audiences or propensity models to downstream tools.
Example tools: Census, Hightouch, Lytics, RudderStack (Reverse ETL)
Data storage
There are a lot of ways to store huge amounts of data now, and it’s cheaper and easier than ever. Unmanaged cloud data warehouses such as AWS RedShift are and have long been popular destinations in Segment, but that popularity is shifting. The storage products that are gaining the most adoption are managed cloud data warehouses, and they are a major contributor to why building an MDS has gotten popular.
Data cloud warehouses are really easy to use. They are “managed” by the vendor. No matter how much data you throw at it, you never have to manage infrastructure, deploy a VM, or have to scale an instance or cluster.
Managed cloud data warehouses also separate compute costs from storage costs. You pay for the storage you use and the compute you use separately, and you only pay for what you use. With most unmanaged cloud data warehouses, your data warehouse instance size determines your storage capacity and your compute capacity. If you run out of storage but are barely utilizing the compute on your instance, you still have to upgrade to the next instance size up and vice versa. This generally makes managed cloud data warehouses more cost-effective than unmanaged ones.
Example tools: BigQuery, Snowflake
Data lakes
Data lakehouses along with new table formats that power them – notably Delta Lake, Apache Iceberg, and Apache Hudi – are gaining traction as well. A data lakehouse is a data lake implemented in an architecture that includes a metadata and governance layer on top of the data store. This lets a data lakehouse function the same way as a data warehouse. So it can be used for BI and analytics in addition to the data science and machine learning workloads that data lakes usually serve.
We are seeing more and more of our largest enterprise customers building data lakehouses and showing interest in these new table formats. Some businesses use them in a medallion architecture as an inexpensive bronze layer to process and clean data before sending it to their managed cloud data warehouse – their gold layer – for analytics. Others have completely replaced their data warehouse with a data lakehouse.
Example tools: Databricks/Apache Spark, Dremio
Data transformation and modeling
Once you have all this customer data in your data warehouse, you have to do something worthwhile with it. Data Scientists still use Python to process data on the warehouse. That hasn’t changed. But now Analysts, Data Scientists, and the new role of Analytics Engineer have rallied pretty heavily behind an open source tool called dbt.
dbt lets you model data with SQL. If you know SQL, you can use dbt. It also lets you build models that have other models as dependencies. dbt builds a directed acyclical graph (DAG) based on the dependencies you define in your models. So when dbt runs a model, it executes all of the prerequisite models in the correct order as per the DAG. After a model runs, the output is materialized – the output data set is turned into a table or view – in the data warehouse.
With its ability to build hierarchical data models, dbt ends up being a collaborative tool for Data teams. Its project structure also lends itself well to version control, and dbt promotes using Git to version control your projects. This helps satisfy the inherent need for version control in a collaborative coding environment.
Example tools: dbt, Looker (LookML), Malloy
Identity resolution & customer profiles
Identity resolution is the process of using 1st party data to build customer profiles based on identified and anonymous interactions across all of your websites and apps. Those customer profiles are used to build audiences, propensity models, etc., that businesses rely on to optimize their customer experience, reduce churn, increase growth, etc.
By definition, CDPs provide some form of identity resolution and customer profiles. Segment has one of the most respected and trusted identity resolution and customer profile offerings on the market in Personas. Yet, no offering that we’ve come across lets you send those identity-resolved customer profiles to your data warehouse. So in an MDS, identity resolution and customer profiles are usually modeled by Data teams with event data stored in the data warehouse and saved to the data warehouse. After building identity-resolved customer profiles from first-party data, you can then join and enrich the profiles with first-party data from your cloud applications and business systems for a more complete and accurate view of your customers.
Building identity-resolved customer profiles is an extremely common use case for companies with an MDS. It is also a time-consuming, labor-intensive process that, to do well, requires a lot of collaboration over time between Data, Marketing, and Product. It took the Segment Data team and Growth Marketing team approximately 2 years of continuous collaboration before we had customer profiles we trusted.
Example tools: Homegrown identity-resolution via dbt (as described in this blog post from dbt)
Analytics & BI
Analytics and business intelligence (BI) tools have been around in more or less the same form for a long time. You use SQL or a visual builder to build charts and visualizations based on data in your data warehouse. Then you can add those charts to dashboards. Each offers different exploration, discoverability, and collaboration features.
Analytics and BI tools give business users a self-serve way to interact with data and generate insights. You’ve probably seen those insights exposed as Sales, Marketing, or Finance dashboards. Our customers use event data from Segment to also build Product dashboards that display analysis geared toward improving the customer experience.
While a lot of the analytics and BI tools haven’t changed much in a long time, new tools like Hex are emerging. Instead of standard charts and dashboards, Hex lets you build interactive data apps. You use a drag-and-drop builder that lets you insert interactive Hex charts, text, images, etc., into a canvas. You can publish data apps and share them.
Example tools: Apache Superset, Hex, Looker, Metabase, Tableau
Data orchestration
Data orchestration tools integrate with data pipeline tools, data transformation tools, data lake and big data tools, and even home-built solutions. They let you build and schedule workflows across multiple data tools. You can use orchestration tools to automate some common as well as some complex tasks.
Here’s a simple example of a workflow that you could build and schedule with a data orchestration tool. Let’s say you need to build a customer list that is refreshed daily. Building it requires firing multiple ETL runs to the data warehouse to refresh object data about your customers. After ETL completes, you have to execute a dbt model on your data warehouse to build the customer list. After dbt completes, reverse ETL has to run to send the customer list to whatever downstream tool your business needs the list in.
Example tools: Apache Airflow, Dagster, Prefect
Data catalog
Data catalogs provide an organized inventory of data in an organization. They automatically collect metadata about your company's data and support adding descriptive documentation about tables or columns. This makes it much easier for stakeholders across your company to search for and discover the data you’re already collecting and storing.
Data catalogs also provide data lineage functionality to help track where the data that you use comes from, where it's copied or replicated, and what data models and dashboards it is used in over time. This makes data debugging easier and can aid in compliance tracking.
Example tools: Alation, Atlan, Castor, Collibra, Stemma/Amundsen
Non-Functional considerations
During our discussions with our customers, we noticed some non-functional aspects of an MDS that are important and frequently subjective – such as privacy & security, data quality, and data observability. These aren’t tasks to be done, but qualities an MDS exhibits. As such, tool categories have not sprung up around all of these areas.
Below are descriptions of the important, non-functional aspects of an MDS that matter to Data teams.
Privacy & security
Privacy & security covers the proper handling of data – consent, notice, and regulatory obligations. Data is a strategic asset, and businesses need to comply with rapidly-changing, industry-standard regulations and adhere to promises made to consumers to protect their data. Common mechanisms include use case or customer-specific data usage controls, PII auto-classification, role- or account-based access controls, and anonymization strategies. Instead of developers, the target customers are data security and data privacy managers, whose jobs are to minimize the risk of data breaches or leakage.
Data quality
Data quality describes how much you trust your data. Data quality can be impacted by the amount and type of data collected, the accuracy of your data, and the recency of your data. Most companies try to assure their data quality with tools and processes that ensure complete, accurate, and fresh data. Investing in data quality will improve trust in your data, reduce time spent navigating and validating data, and ultimately allow your business to grow faster.
Example tools: Twilio Segment (Protocols), Trackingplan
Data observability
Data observability is the ability to understand the health and state of data in your system in near real-time. It’s the equivalent of Dev Ops for your data and includes tools to monitor, trace, and triage data incidents. The net effect is improved data quality, reduced downtime, and, when done well, preventative maintenance of your data.
Example tools: Acceldata, Databand, Great Expectations, Metaplane, Monte Carlo
Data freshness
We define “data freshness” as “the time it takes for the effect of an event ingested through Segment to become observable and usable by a consuming application.” Our customer research shows that most use cases can be met with a 5-minute SLA – with the exceptions of transactional messages and on-site personalization which requires data freshness in seconds.
Cloud data warehouses have some limitations when it comes to data freshness. Depending on multiple factors, latency can vary but typically ends up being 5 minutes or longer. So, today, use cases with a more aggressive SLO for data freshness might not be satisfied by what a data warehouse-centric architecture on its own can achieve. With that said, we do believe warehouses will be able to offer data freshness in seconds in the future
Build your data foundation today with Twilio Segment
Segment is a foundational piece of a Modern Data Stack. The event data we collect and pipe to your data warehouse powers your MDS. Integrations are one of the most challenging parts of building a data stack, and we make them easy. And our identity-resolved customer profiles, offered through Personas, solve some of the most common MDS use cases.
Sign up for a free Twilio Segment workspace and start building the right foundation for your MDS today.