How Data Engineers Use Automation to Give Your Business a Data-Backed Foundation
- Published on
- Written by
- Name
- Gavin Johnson

This post was originally published on The New Stack.
Every task that your company performs that involves someone on your data team sending a spreadsheet full of data is an opportunity for improvement. Not only does having multiple people handling your data increase the likelihood of incorrect data being used, but it also makes your data less secure. Also, everyone applies their own layers of transformations, making the data less consistent.
Data engineering can solve these problems for you.
Your data engineers build pipelines that collect, share, and store your data. They help automate the data-driven processes that your company executes, applying programmatic execution and removing human delays and human error from the equation as much as possible. Data engineers remove emails, spreadsheets, and manual processing from your data pipelines. This frees teams across your company to innovate — giving them a stable, data-backed foundation to execute and experiment from.
Data Engineering Lends Itself to Automation
The primary responsibility of data engineers is to provide accurate, high-quality, and complete data to all of your teams, in a way that is easy to access. In this post, we’ll cover the benefits of automating tasks in six key areas:
- Data collection
- Data sanitization
- Data cleansing
- Data warehousing
- System integrations
- Reverse-ETL — data movement out of the warehouse and into applications
Here’s a block diagram showing the correlation between the six key areas of data engineering:
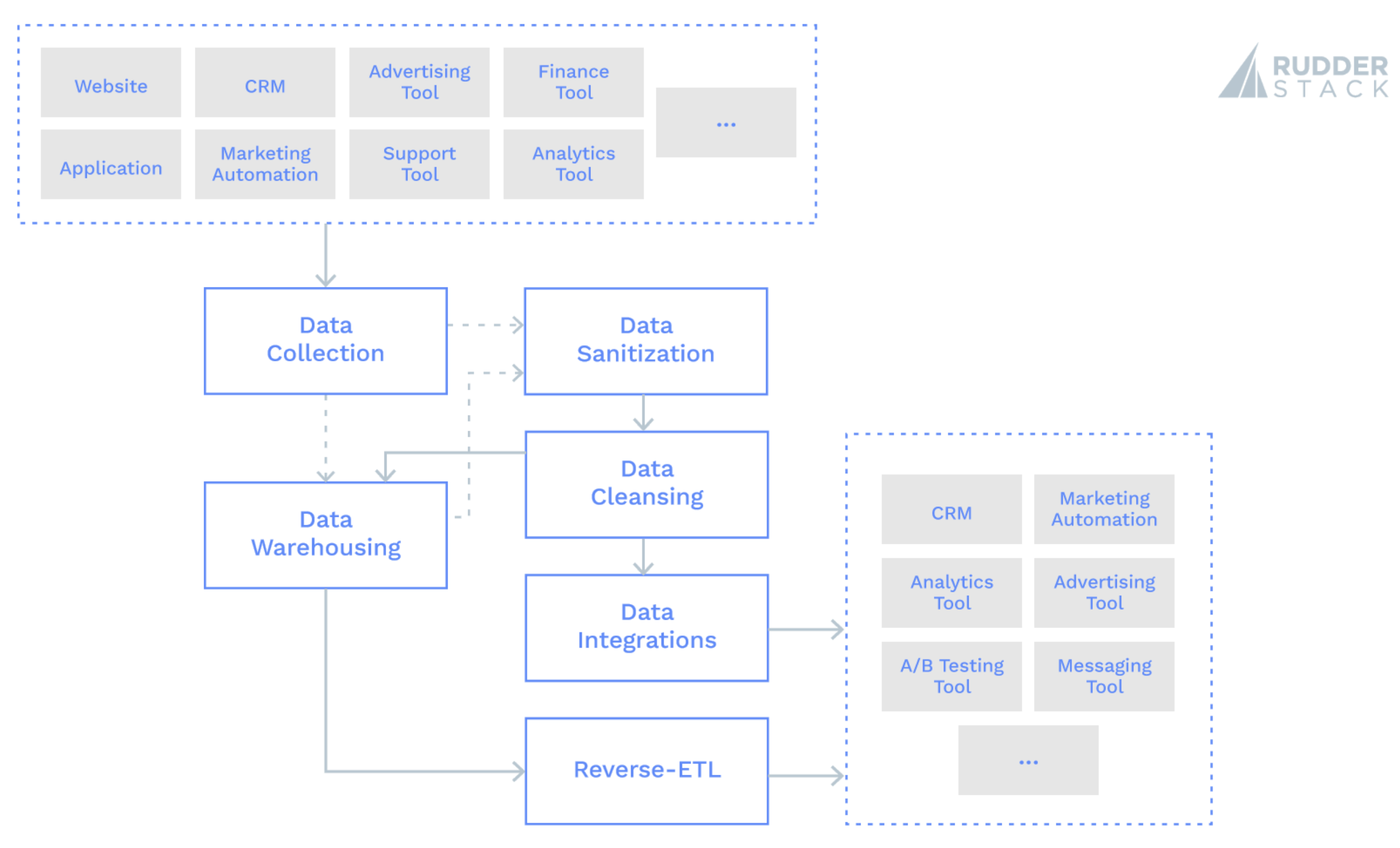
Data Collection
The indicator of successful data collection is the accuracy and consistency of your data. Suppose that your data is inconsistent, incorrect, or you’re missing expected data in your data sets. In those cases, data scientists and analysts have difficulty working with it. Other applications may have trouble activating it, and it becomes less useful for AI/ML use cases.
The more standardized and automated your data collection process, the more consistent and accurate your data will be. Automation ensures that event data is delivered consistently and that ETL pipelines are successful and run on a reliable schedule. The dream scenario for any data engineer is building a data pipeline, validating it, and never having to touch it again because it’s standardized, automated, and fault-tolerant.
Data Sanitization
Data sanitization is the process of removing private or sensitive information from your data. You can sanitize data during the collection process, pre-delivery or post-delivery. In either case, the indicator of successful data sanitization is accuracy and consistency — e.g., is it being applied to the correct fields, and is it being applied across all records?
The more standardized and automated your data sanitization process, the better your data privacy and the lower your potential for exposing sensitive data. Automation ensures that you aren’t storing sensitive data unless necessary and, when necessary, only the appropriate people have access to it.
Data Cleansing
Along with data sanitization, data cleansing is the most time-consuming process in data engineering. Data sanitization and cleansing require inspecting every record and making conditional updates; and that requires a lot of compute time, regardless if performed by a human or computer.
Data cleansing is removing or correcting bad data or unnecessary data. To make your data easier to work with and more accurate, you will frequently delete or update inaccurate data or incomplete or inconsistent data with your data set. Data cleansing processes need to be accurate and consistent — applied evenly across your data and only touching bad data.
The more standardized and automated your data cleansing process, the higher quality and more usable your data will be. Automation ensures that you are only storing good data.
Data Warehousing
Data warehousing is storing your data in your data warehouse, to be accessible for analysis and BI/ML use cases. Your data warehouse is often your most used data destination. The need for consistency and accuracy applies to the data warehousing process.
The more standardized and automated your data warehousing process, the more complete and useful your data set will be. Automation ensures that your data is delivered and stored consistently — in a logical format and schema, and on the schedule that you expect.
Data Integration
Data integration is connecting data between systems. From a technical standpoint, data integrations work similarly to data warehousing: you connect data from a source to a destination, just like you do with a data warehouse. But data integrations are typically used less for storage and more for activation, which requires them to deliver data much closer to real-time than with data warehousing. Also, there are a ton of different tools you may want to integrate with, but there is usually only one data warehouse you integrate with. So the difficulty and importance of standardization and automation are both greater for data integrations. Consistent, accurate data across your systems makes teams more cohesive and enables them to act on the most up-to-date data.
The more standardized and automated your data integration process, the less work your data engineers will have to do to maintain your pipelines, the more quickly you can experiment with new tools, and the more flexible and creative your teams can be. Automation ensures that all of your tools and teams are working with the same, high-quality data.
Reverse-ETL
Reverse-ETL is the new kid on the block for data engineers, but it’s just an extension of data integration that relies on data warehousing. Reverse-ETL is sending data stored in your data warehouse out to the tools you use. Data warehouses have traditionally been destination-only, so flipping the data flow and turning them into a source for data integrations is novel and can help solve many difficult use cases. Like every other process that a data engineer does, consistency and accuracy are extremely important for reverse-ETL.
Standardizing and automating the reverse-ETL process has the same benefits as data integration. However, the data coming from the reverse-ETL process is more valuable to your business than normal event stream or ELT/ETL data. Data sent via reverse-ETL is typically post-analysis or post-modeling and contains insights you want to activate. So any faults in your reverse-ETL process have amplified negative impacts.
Your Data Engineers Should Standardize the Tools They Use Too
Data engineers have long used a variety of tools to help with these tasks. They have ETL tools, ELT tools, event streaming tools, and now reverse-ETL tools at their disposal. These tools make the responsibilities of a data engineer possible and also make standardizing and automating these tasks easy. Just as your data engineers want to standardize and automate the tasks they execute, your data team should standardize the tools they use too.
Allowing your data team to use whatever tools they want might seem liberating, but it’s not efficient. Licensing will be more complex and expensive than necessary, your data will be in inconsistent schemas, and you may end up rebuilding full pieces of functionality for each tool (for things like data sanitization and data cleansing).
Consolidating your data teams on a best-of-breed tool for each type of data flow makes a lot of sense. One tool for event streaming, one tool for ELT/ETL, and one tool for reverse-ELT. This approach is more standardized, but it’s still not optimal. You’ll pay three license fees, your data schemas will still differ across tools, and you may still end up re-building full pieces of functionality for each tool — but at least you’re limited to three tools.
The best approach is to unify your teams on a single, complete solution. You only pay one licensing fee, your data schemas will be similar across stores, and you can better reuse the functionality you’ve built. Moreover, your data team only has to learn one pipeline tool; and they know exactly where to go if they are having problems with any of their data pipelines.
RudderStack is the single, complete solution for your data engineers to build all of the customer data pipelines your company needs — event streaming, ELT/ETL, and reverse-ETL. It allows you to easily build pipelines connecting your whole customer data stack. Sign up for RudderStack Cloud Free today.